Comparison of different setups for remote distributed computing to analyze real time Twitter data.
We performed an empirical analysis of the computation time for processing Twitter data. The task was to compute the \(n\) most used hashtags in a dataset of tweets of variable size, downloaded using Twitter’s API.
The setups to be compared were using a single machine (M5D.2XLARGE, with 8 CPUs, 32GB of memory and 8GB of hard drive space, running Ubuntu 18.04) and a cluster of 4 identical ones. All instances were running remotely in AWS. The former setup uses a simple sequential Python program, while the latter is using a version adapted for a distributed environment using Spark.
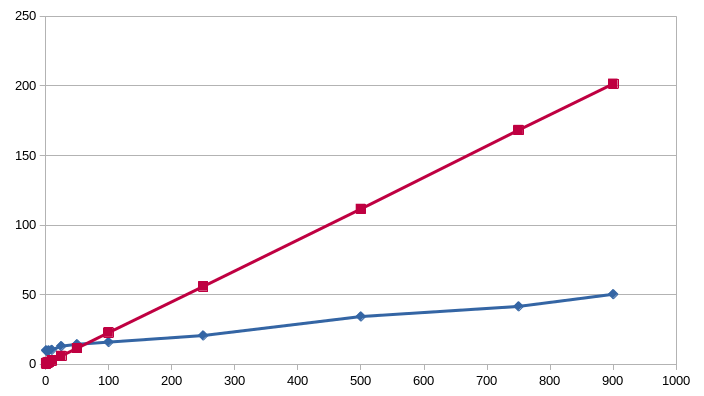
The measured times show that, as expected, the computation time for the sequential setup (red) grows linearly with the size of the dataset and so does the distributed case (blue), but with a slope of 1/4 of the original.
The vertical axis corresponds to the computation time (in seconds), while the horizontal one is a replication hyperparameter \(r\) proportional to the size of the dataset (the total size is \(r \times 5.76\)MB, with the last value of \(r=900\) corresponding roughly to a dataset of 5GB, close to the limit for the machines’ disk space).
It can also be seen that for small values of \(r\) (i.e. few data) the sequential case is faster, since the speedup gained by distributing the computation does not compensate its overhead. But as soon as the data grows this overhead is negligible and the distributed version’s performance is much faster.